Web Scaling - using Redis as Cache
Redis is such a great technology. Unfortunately, there’s still people who don’t know Redis or don’t know that Redis can be used as a Cache System to improve the speed of responses.
Why Redis
Well, let’s start this discussion remembering how a common Relational Database basically works: Suppose we’re using a MySQL, every time your app sends a request to the MySQL client, the MySQL client gotta make a trip to the hard drive to get the data asked in the request, this can become a problem if the data asked in request is big… and if there are many requests at the same time, this can generate a huge latency, annoying users or worse.
This is where Redis comes into play, Redis is a key-value database that will be running and storing data inside your memory, if you remember the basic of computers architecture:
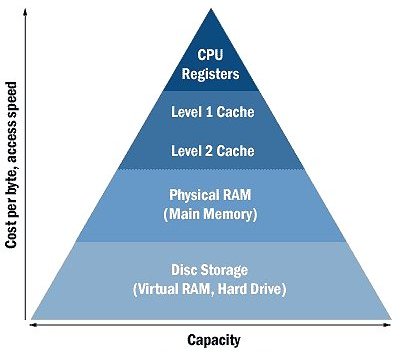
It’s way faster to access data in memory (Physical RAM, main memory) than to access data in the Hard Drive, so it’s easy to notice that if the data that the application wants to access is inside the main memory, it’s way easier to reach to that data than if it was stored in the Hard Drive.
So, like I said, Redis will be storing its data inside the memory, but you may ask yourself: “but what if I turn off the machine?? isn’t the ram memory volatile? " Yes, that’s why Redis will be flushing the data to the hard drive from time to time, it’s up to you to choose this time between flushes, it’s all about Performance vs. Security.
So, What we’ll be doing is just:
note that this print is taken from a talk I gave in my country, so it’s in portuguese. aplicação = application, Não acha key = key don’t found, retorna dados = return data
As you can see: So much win. We avoided redundant trips to the disk.
Now that we understand the concept of what we’ll be doing, the code becomes very easy to implement, here’s a simple idea (thougt it can be improved and extended in many ways, but it can demonstrate the idea we’re working here)
So, after you create the correct database, populate the database (there’s a function in the code for that) and change username/password/dbname in the code, we’ll run the app.py and go to localhost:port-you-exposed.
What will happen?
1. The first time you access it, it will take a few seconds to get the data from the MySQL
2. The second time you access it, it will take just a few milliseconds to get the same data from redis
In my computer the result was:
first access: 45861 milliseconds
second access: 5ms
I know, right? That’s just blazing fast!
And it can save a lot of computational resources and human time. Now, with this logic applied to one method (the method to get users), we can apply it to whichever method we want, or we can even create a generic decorator and annotate the methods that we want do the caching!!