6 minutes read | published @ December 13, 2017
On machine learning enhanced software systems
I have been brewing the idea of using machine learning to improve software systems since 2016. It was pretty vague and broad, without an actionable plan. I just had the intuition — the software configuration and tuning, especially after the adoption of microservices, was getting too complex.
The increasing complexity of configuring and tuning systems
If you have enough experience in the software industry, then it’s very likely that you’ve struggled with either a configuration problem or a tuning problem.
Configuration and tuning problems are pretty common and can lead to really bad outages. They often occur when:
-
Some parts of the system are poorly or wrongly configured, or
-
A configuration that worked before now doesn’t work because the context of the system has changed.
Think of a number of database replicas and their writing schemes. Or in Postgresql, think of the number of shared buffers, effective cache size, and the min and max wal size.
If wrongly configured from the start, it won’t work in the given context, plain and simple. What’s more interesting, though, is if it’s correctly configured, it might work at a given time. But as the context changes — system workload, system resources usage, overall system architecture — the system will behave poorly. Or, even worse, an outage might happen.
This will, inevitably, lead to manually-performed operations and the creation of heuristics. In other words, it will lead to:
Oh, we should set X to A, when workload is T, but it should be A+10 when workload is T+100 and we have system resources usage above 80%… I guess. Or maybe let’s just up a queue in front of this component, queues solve everything, right?
Now multiply this scenario by tens or hundreds of services. Think for a second about the cognitive burden resulting from these configurations.
This is not a new concern. In 2003, Ganek and Corbi discussed the need for autonomic computing to handle the complexity of managing software systems. They noted that managing complex systems became too costly, labor-intensive, and prone to error due to the pressure engineers felt while maintaining them. This increased the potential of system outages with a concurrent impact on business.
Even nowadays, most of the configurations and tuning of the systems are performed manually, often in run-time, which is known to be a very time-consuming and risky practice. Check out these two links (here and here) to read more about it.

The need for autonomic computing
Most decisions to configure and tune the system are made based on the context — there are many different variables such as workload, number of instances of some services, resources usage, and more. So why not delegate these tasks to something that excels at exactly that? Machine learning sounds like a feasible tool for the job.
After starting my Masters at the University of British Columbia, I kept working on this idea. It seemed interesting although quite weird, and, sometimes, unpractical and impossible to implement.
To my surprise, I realized I wasn’t alone. Some very interesting people were working on these ideas — so it might not be that weird, unpractical, and impossible.
Recently, Jeff Dean — a man that I admire a lot — gave a talk at NIPS 2017 talking about machine learning for systems, where he stated:
Learning should be used throughout our computing systems. Traditional low-level systems code (operating systems, compilers, storage systems) does not make extensive use of machine learning today. This should change!
Computer Systems are filled with heuristics: compilers, networking code, operating systems. Heuristics have to work well “in general case”. [They] generally don’t adapt to actual pattern of usage and don’t take into account available context
Learning in the core of all of our computer systems will make them better/more adaptive.
I was in complete awe when I read this. One of the engineers I admire the most was talking about the very same ideas I’ve been thinking about and working on.
This led me to think that it’s not only interesting but natural to think about enhancing software systems with machine learning. Throughout the whole software stack, we have many heuristics that, although they work well, could be improved by machine learning.
Is it challenging and potentially risky? Yes, most definitely. Especially given that interpretability, apparently, has become a secondary goal in the machine learning community. How can we interpret and explain the decisions made by neural nets?
However, with that said, these obstacles shouldn’t hinder scientific and technological progress. Yes, we should question old paradigms and try to improve things.
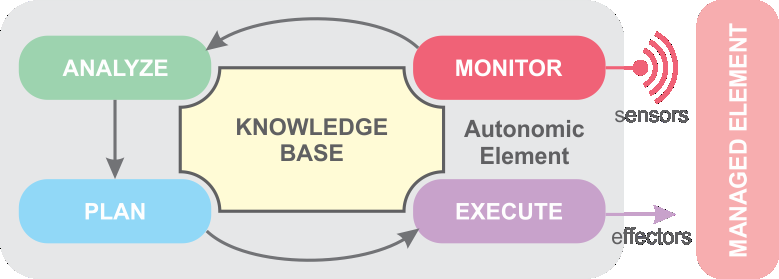
Towards machine learning-enhanced software systems
As Jeff Dean pointed out: we need to find practical ways to make systems data-aware. We need systems that collect metrics and metadata about themselves. To achieve this, we could learn a thing a two from the ideas in systems observability and instrumentation. We have been instrumenting systems for decades, and the data is already there.
We also need to find practical and clean ways to integrate machine learning components into software systems, making learning a first-class citizen in the system. This will lead to systems that learn how to improve themselves, beating heuristics and manually-performed operations. Think about this for a second. It does sound cool and feasible.
I would also add that we need practical and clean ways to propagate the decisions made by the learned models to the rest of the system. This would allow the system to have self-adaptive capabilities. Here, we could learn something from the control theory community.
The general idea is fairly simple: make a system learn about its behavior by training a model on its context. Then allow it to change its structures and configurations in order to optimize for a certain scenario. Now implement this idea in such a way that it could be possible to integrate it into many kinds of systems.
Summary
The most interesting questions I have in mind are:
-
Can self-adaptation by learned models lead to more stable, faster, safer software systems? Can it reduce the need for manually configuring and tuning systems, allowing engineers to focus on more important tasks?
-
Can this be easily integrated into software systems, requiring only small changes to the codebase?
-
Can this work with low overhead?
It is worth noting that this would not replace good engineers, but would rather free the engineers’ cognitive abilities to focus on what matters.
I genuinely believe that this will become a trend in the next few years. I myself am working on these ideas as part of my graduate studies, and I will be posting the results of my research, so stay tuned.
architecturesoftwaremachine-learningthoughtssystems
1103 Words
2017-12-13 00:00 +0000
8bd269c @ 2020-02-08